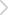本站 3 月 6 日消息,研究表明,强化学习可以显著提高模型的推理能力,例如 DeepSeek-R1 通过整合冷启动数据和多阶段训练,实现了最先进的性能,使其能够进行深度思考和复杂推理。
阿里云通义千问官方今日宣布推出最新的推理模型 QwQ-32B。这是一款拥有 320 亿参数的模型,其性能可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 媲美。
这一成果凸显了将强化学习应用于经过大规模预训练的强大基础模型的有效性。此外,我们还在推理模型中集成了与 Agent 相关的能力,使其能够在使用工具的同时进行批判性思考,并根据环境反馈调整推理过程。
目前,QwQ-32B 已在Hugging Face(https://huggingface.co/Qwen/QwQ-32B)和ModelScope(https://modelscope.cn/models/Qwen/QwQ-32B)开源,并采用了 Apache 2.0 开源协议。本站提醒,用户也可以通过 Qwen Chat(https://chat.qwen.ai/?models=Qwen2.5-Plus)直接进行体验。

性能方面,阿里云对 QwQ-32B 测试了数学推理、编程能力和通用能力,并展示了 QwQ-32B 与其他领先模型的性能对比,包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 以及原始的 DeepSeek-R1。
在测试数学能力的 AIME24 评测集上,以及评估代码能力的 LiveCodeBench 中,千问 QwQ-32B 表现与 DeepSeek-R1 相当,远胜于 o1-mini 及相同尺寸的 R1 蒸馏模型;在由 Meta 首席科学家杨立昆领衔的“最难 LLMs 评测榜” LiveBench、谷歌等提出的指令遵循能力 IFEval 评测集、由加州大学伯克利分校等提出的评估准确调用函数或工具方面的 BFCL 测试中,千问 QwQ-32B 的得分均超越了 DeepSeek- R1。
阿里云表示,这是 Qwen 在大规模强化学习(RL)以增强推理能力方面的第一步。通过这一旅程,不仅见证了扩展 RL 的巨大潜力,还认识到预训练语言模型中尚未开发的可能性。
在致力于开发下一代 Qwen 的过程中,阿里云计划将更强大的基础模型与依托规模化计算资源的 RL 相结合,从而使其更接近实现人工通用智能(AGI)。此外,阿里云正积极探索将智能体与 RL 集成,以实现长时推理,目标是通过推理时间扩展来释放更高的智能,敬请期待。